The Anti-Hallucination Stack: Engineering LLM Products That Are Accurate Enough to Trust
Hallucination is not a bug you fix. It is a property of the model that you design around. The engineering work involves building detection layers, confidence mechanisms, and fallback behaviors that make a product trustworthy, even when the model is wrong.
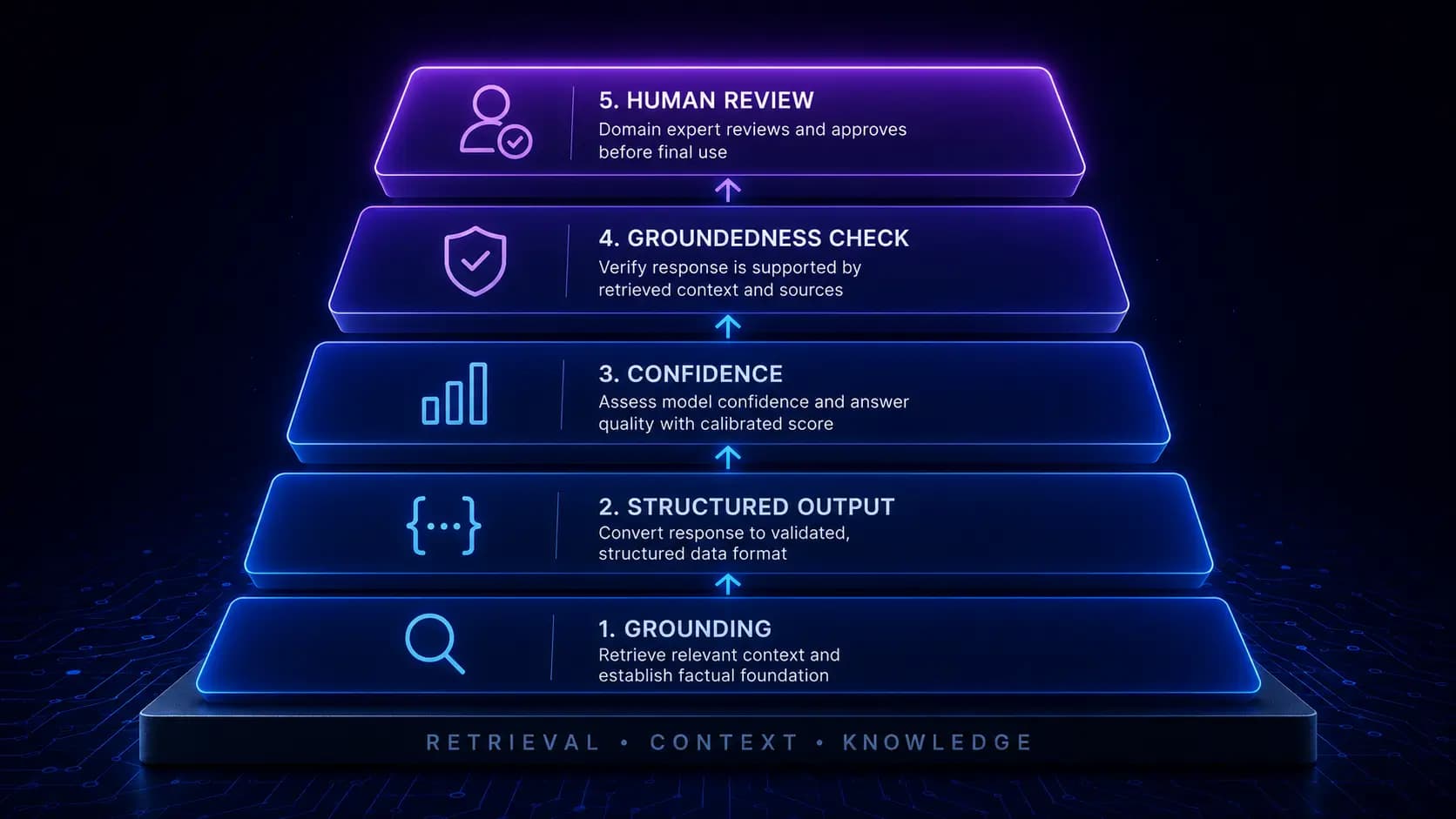
Every LLM product ships with hallucination risk. This is not a failure of engineering or a solvable problem in the conventional sense; it is a fundamental property of how large language models work. The engineering challenge is not eliminating hallucination but building systems robust enough that hallucinations are detected before they reach users, or are narrow enough in scope that when they do reach users, the consequences are limited and recoverable.
This post covers the technical stack we use to minimize hallucination impact in production LLM products.
Layer 1: Constraining the generation space
The most effective anti-hallucination measure happens before generation begins: constraining what the model is allowed to generate.
Grounding in retrieved context
RAG (Retrieval-Augmented Generation) is the foundational anti-hallucination technique. Instead of asking the model to generate from memory, you retrieve the relevant information from your knowledge base and instruct the model to answer from the provided context only.
The critical prompt instruction:
const systemPrompt = `
You are a healthcare documentation assistant. Answer the user's question using ONLY the information
provided in the context sections below. If the answer is not contained in the provided context,
respond with "I don't have information about that in the available documentation."
DO NOT:
- Add information not present in the provided context
- Make inferences or extrapolations beyond what the context states
- Use your general knowledge about medicine or healthcare to supplement the context
Context:
\${retrievedChunks.map(c => `[Source: \${c.source}]\n\${c.content}`).join('\n\n')}
`The explicit prohibitions, "DO NOT add information not present in the context", are important. Testing on our RAG systems has consistently shown that explicit negative instructions reduce hallucination rates compared to only positive instructions ("only use the provided context").
Structured output constraints
When the model's output is a structured data object rather than free text, the JSON schema enforces that the model cannot generate arbitrary content. A model constrained to return { answer: string, sourceChunks: string[], confidence: "high"|"medium"|"low" } cannot hallucinate by inventing unstructured content; it can only hallucinate within the boundaries of those fields.
Temperature control
Temperature controls the randomness of generation. Lower temperature (0.0 to 0.3) produces more deterministic, conservative outputs. For factual Q&A from a knowledge base, we use temperature 0.1 to 0.2. For creative or summarization tasks where some variation is desirable, 0.5 to 0.7. We never use high temperature (>0.8) for any task where factual accuracy matters.
Layer 2: Confidence estimation
The model generates a confidence score with its response, but model self-reported confidence is notoriously miscalibrated, since models can be very confident in wrong answers and uncertain about correct ones. We augment model confidence with retrieval-based confidence.
Retrieval confidence
The maximum cosine similarity between the query embedding and the top retrieved chunk is a proxy for how well the knowledge base covers the query. Low similarity means the query is not well-covered by available content, which should reduce confidence regardless of what the model generates.
interface ConfidenceResult {
modelConfidence: 'high' | 'medium' | 'low'
retrievalScore: number // max cosine similarity of top chunk, 0-1
groundednessScore: number // % of claims grounded in retrieved context, 0-1
compositeConfidence: 'high' | 'medium' | 'low' | 'insufficient'
}
function calculateCompositeConfidence(
modelConf: 'high' | 'medium' | 'low',
retrievalScore: number,
groundednessScore: number
): ConfidenceResult['compositeConfidence'] {
// If retrieval score is low, the knowledge base doesn't cover this query
if (retrievalScore < 0.4) return 'insufficient'
// If groundedness is low, the model is generating beyond its context
if (groundednessScore < 0.6) return 'low'
// Composite score
const modelScore = modelConf === 'high' ? 1 : modelConf === 'medium' ? 0.6 : 0.3
const composite = (modelScore * 0.3) + (retrievalScore * 0.4) + (groundednessScore * 0.3)
if (composite >= 0.75) return 'high'
if (composite >= 0.5) return 'medium'
return 'low'
}
Layer 3: Post-generation groundedness check
After the model generates a response, a separate verification step checks whether the factual claims in the response are supported by the retrieved context. This is the most expensive layer in the anti-hallucination stack but the most effective at catching the cases where layers 1 and 2 fail.
Claim extraction
The first step is to decompose the model's response into individual factual claims:
async function extractClaims(response: string): Promise {
const result = await openai.chat.completions.create({
model: 'gpt-4o-mini', // cheaper model for this preprocessing step
messages: [
{
role: 'system',
content: 'Extract all discrete factual claims from the following text. Return each claim as a separate item in a JSON array. A claim is a statement that asserts something to be true. Do not include hedges or qualifications, just the core factual assertions.'
},
{ role: 'user', content: response }
],
response_format: { type: 'json_object' },
})
const parsed = JSON.parse(result.choices[0].message.content!)
return parsed.claims as string[]
}Claim verification
async function verifyClaims(
claims: string[],
context: RetrievedChunk[]
): Promise<{ claim: string; supported: boolean; evidence?: string }[]> {
const contextText = context.map(c => c.content).join('\n\n')
return Promise.all(claims.map(async (claim) => {
const result = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{
role: 'system',
content: `Determine whether the following claim is directly supported by the provided context.
Return JSON: { "supported": boolean, "evidence": "exact quote from context that supports this claim, or null if not supported" }`
},
{ role: 'user', content: `Claim: \${claim}\n\nContext:\n\${contextText}` }
],
response_format: { type: 'json_object' },
})
const parsed = JSON.parse(result.choices[0].message.content!)
return { claim, ...parsed }
}))
}
// Calculate groundedness score
const verificationResults = await verifyClaims(claims, retrievedChunks)
const groundednessScore = verificationResults.filter(r => r.supported).length / verificationResults.lengthA groundedness score below 0.7 (70% of claims supported) triggers a flag and may prevent the response from being delivered to the user, instead returning an "I'm not confident enough in this answer" message with a recommendation to contact a human.
Layer 4: Fact-check against authoritative sources
For high-stakes domains, healthcare, legal, and financial, we add a fourth layer: verification against an authoritative external source when one is available. For medication information, this might be a verified drug database; for clinical guidelines, a curated clinical knowledge base; and for legal citations, a legal information service.
This layer is application-specific and expensive, so we apply it only to the highest-risk claims, such as those that involve specific numbers (dosages, legal thresholds, and financial figures), proper nouns (drug names and legal citations), or claims where the model's confidence is only medium.
Layer 5: Human review queuing
For responses that pass the groundedness check but contain low-confidence claims, or for responses in the "medium" composite confidence band, we queue for asynchronous human review. The response is delivered to the user with a disclosure ("This answer has been generated by AI and is pending review by a specialist"), and a human reviewer is notified to verify the response.
async function processResponse(
query: string,
modelResponse: string,
confidence: ConfidenceResult
): Promise {
if (confidence.compositeConfidence === 'insufficient') {
return { type: 'no-answer', message: "I don't have reliable information about that. Contact support." }
}
if (confidence.compositeConfidence === 'high') {
return { type: 'answer', content: modelResponse, reviewed: false }
}
if (confidence.compositeConfidence === 'medium') {
await humanReviewQueue.add({ query, response: modelResponse, confidence })
return {
type: 'answer-pending-review',
content: modelResponse,
disclosure: 'This answer is AI-generated and pending specialist review.',
}
}
// Low confidence, do not deliver the AI response
await humanReviewQueue.add({ query, confidence, priority: 'high' })
return {
type: 'escalated',
message: 'This question requires specialist review. We will respond within 24 hours.',
}
}Measuring the stack's effectiveness
The anti-hallucination stack needs its own metrics:
- Hallucination rate: % of delivered responses containing at least one unsupported claim. Measured by periodic human audit of a sample of responses.
- Suppression rate: % of queries that result in "insufficient confidence" or "escalated" rather than a delivered answer. High suppression rate means either the knowledge base is too thin or the thresholds are too strict.
- Groundedness score distribution: The P25, median, and P75 of groundedness scores across all processed queries. A declining median signals drift in knowledge base coverage or query distribution.
- Human review resolution time: How long it takes a reviewer to process items in the review queue. If this grows, the queue becomes a bottleneck and medium-confidence responses are stuck pending review.
The goal is a system where users receive accurate answers automatically for the well-covered queries, receive disclosed-but-timely answers for the moderately covered queries, and are escalated to a human for the outliers, rather than a system that confidently answers everything and is wrong some percentage of the time.
If you are building an LLM product where accuracy is non-negotiable, healthcare AI, legal research tools, and financial planning software, and want to implement an anti-hallucination stack that fits your specific accuracy requirements, we can help you design and build it.

Related service
AI Development & Automation
Production RAG pipelines, LLM integrations, and AI workflow automation for healthcare and e-commerce.
Written by
Founder & CEO
Gaurang Ghinaiya is the Founder & CEO of Nexios Technologies. He is passionate about building innovative software solutions that drive business growth. With years of experience in technology leadership, he guides teams toward excellence.