Why AI Chatbots Hallucinate and How to Fix It
Hallucination is an inherent property of how language models work, not a bug that will be patched. Here is how to architect AI systems that cannot hallucinate about the things that matter.

An AI chatbot that confidently answers a question it does not know the answer to is not a minor usability issue. In a customer service context, it means wrong information delivered with false authority. In a clinical or legal context, it means potential harm. Hallucination, the phenomenon where a large language model generates plausible-sounding but factually incorrect content, is an inherent property of how these models work, not a bug that vendors can patch in a future release. The question for builders is not how to eliminate hallucination from the base model. It is how to design a system that cannot hallucinate about the things that matter to your users.
Why language models hallucinate
A large language model is trained to predict the next token in a sequence, the most statistically plausible continuation of the text it has seen. It does not have a fact database it consults before answering. It does not know what it knows. When asked a question for which its training data contains limited or conflicting signal, it generates a plausible-sounding answer anyway, because generating plausible text is what it was trained to do.
The model that confidently cites a non-existent court case or describes a clinical procedure incorrectly is not malfunctioning. It is functioning exactly as designed, just applied to a question where "plausible" and "true" diverge significantly. This is a structural property of the architecture, not a calibration issue that improves linearly with model size. Larger models hallucinate less frequently, but they hallucinate more convincingly, which is arguably worse in high-stakes applications where users have more trust in more capable-seeming systems.
The categories of hallucination that damage businesses
Not all hallucinations carry the same risk. There are four categories worth distinguishing:
Factual hallucination: the model asserts a fact that is wrong. A product chatbot that states a product has a feature it does not have; a legal chatbot that cites a statute with the wrong section number; or a medical chatbot that recommends a contraindicated drug combination. These are the hallucinations that generate legal liability.
Temporal hallucination: the model answers from its training data as if it is current, when the information has changed. Pricing, personnel, policies, and regulatory requirements all change. A model trained in 2023 answering questions about current pricing in 2025 is systematically wrong without knowing it is wrong.
Confabulation: the model invents plausible-sounding details to fill gaps in its knowledge. References that do not exist; contact information that is not real; or case studies attributed to organizations that never happened. These are particularly dangerous because they are constructed with the same stylistic confidence as accurate information.
Source attribution failure: the model summarizes a real document incorrectly, attributing a claim to the source that the source does not actually make. This is common in legal and compliance contexts where the precise wording of a policy or statute matters.

How retrieval-augmented generation changes the equation
RAG fundamentally reframes the model's task. Instead of asking "what do you know about X?", you are asking "given these specific documents, what is the answer to X?" The model is constrained to answer from what it was given, not from the general statistical patterns in its weights. This addresses three of the four hallucination categories directly.
Factual hallucination is reduced because the model is anchored to specific retrieved content. Temporal hallucination is eliminated if your retrieval index is kept current. Confabulation is addressed by the instruction design, explicitly telling the model to return a "not found" response when the retrieved context does not contain a sufficient answer, rather than generating a plausible-sounding response from general knowledge.
Source attribution failure is reduced by including explicit citation instructions, requiring the model to quote the relevant passage from the retrieved document before summarizing it. When the model must show its work, discrepancies between the source and the summary become detectable.
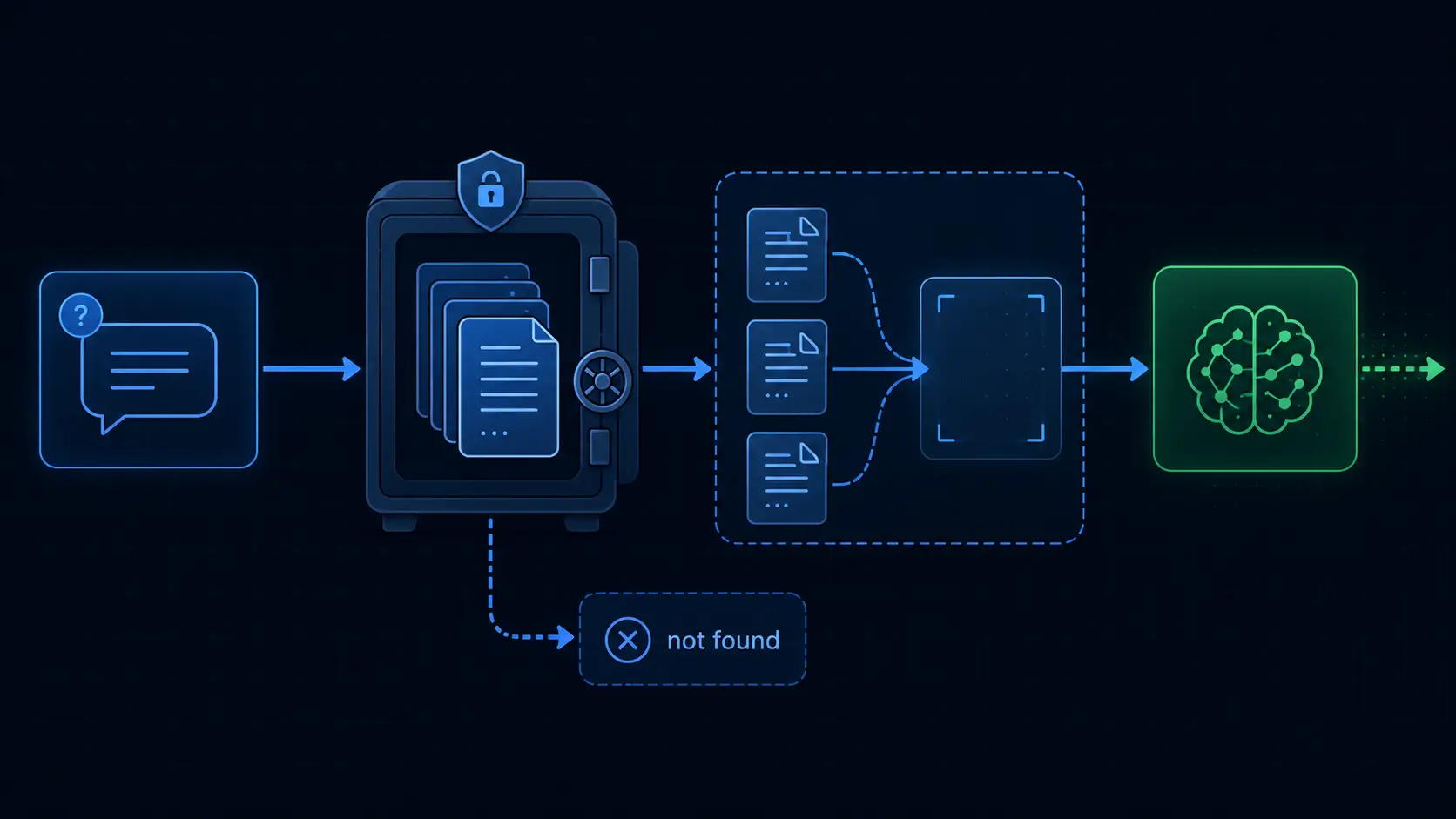
The engineering details that separate reliable RAG from unreliable RAG
The engineering challenge in anti-hallucination RAG is not the retrieval; it is the instruction design and the guard rails. The system prompt must explicitly instruct the model not to answer from prior training knowledge, to cite its sources, and to express uncertainty when the retrieved context is ambiguous. Retrieval quality must be high enough that the most relevant passages are actually in the context window for hard questions. And output validation, checking whether the generated answer is actually supported by the retrieved context, is worth implementing for high-stakes applications.
Temperature matters more than most teams realize. A RAG system should run at temperature 0.0 to 0.1. Higher temperatures increase response variability and creativity, exactly the opposite of what a knowledge retrieval system needs. Every notch above 0.1 is a notch toward generating plausible rather than accurate responses.
Confidence thresholding is the layer most implementations skip. When the retrieved context scores below a similarity threshold, the system should return "I don't have information about that" rather than passing low-quality context to the model. A model given poor context does not respond "I'm uncertain." It generates a confident answer from whatever fragments it was given. The confidence threshold prevents the model from ever seeing bad context in the first place.
What "I don't know" is actually worth
The result is a chatbot that knows the limits of what it knows, which is far more valuable than one that always has an answer. In production RAG systems we have shipped, roughly 25 to 30% of queries fall below the retrieval confidence threshold and receive the fallback response. This is not a failure metric; it is a quality control mechanism. It means the system is accurately representing the boundaries of its knowledge base rather than generating confident answers in gaps where no reliable information exists.
Users trust a system that says "I don't have that information" far more than one that gives a wrong answer with authority. The wrong answer does not just fail; it actively damages trust in every subsequent answer, including the correct ones. Design the failure case first. The success case is easier.
Written by
Founder & CEO
Gaurang Ghinaiya is the Founder & CEO of Nexios Technologies. He is passionate about building innovative software solutions that drive business growth. With years of experience in technology leadership, he guides teams toward excellence.