RAG Pipeline Design for Non-Hallucinating AI: What We Learned Shipping to Production
Most RAG implementations that work in demos fail in production. Here's the architecture, including the chunking strategy, embedding model choice, hybrid retrieval, and confidence thresholding, behind a pipeline that achieves over 80% retrieval accuracy at scale.
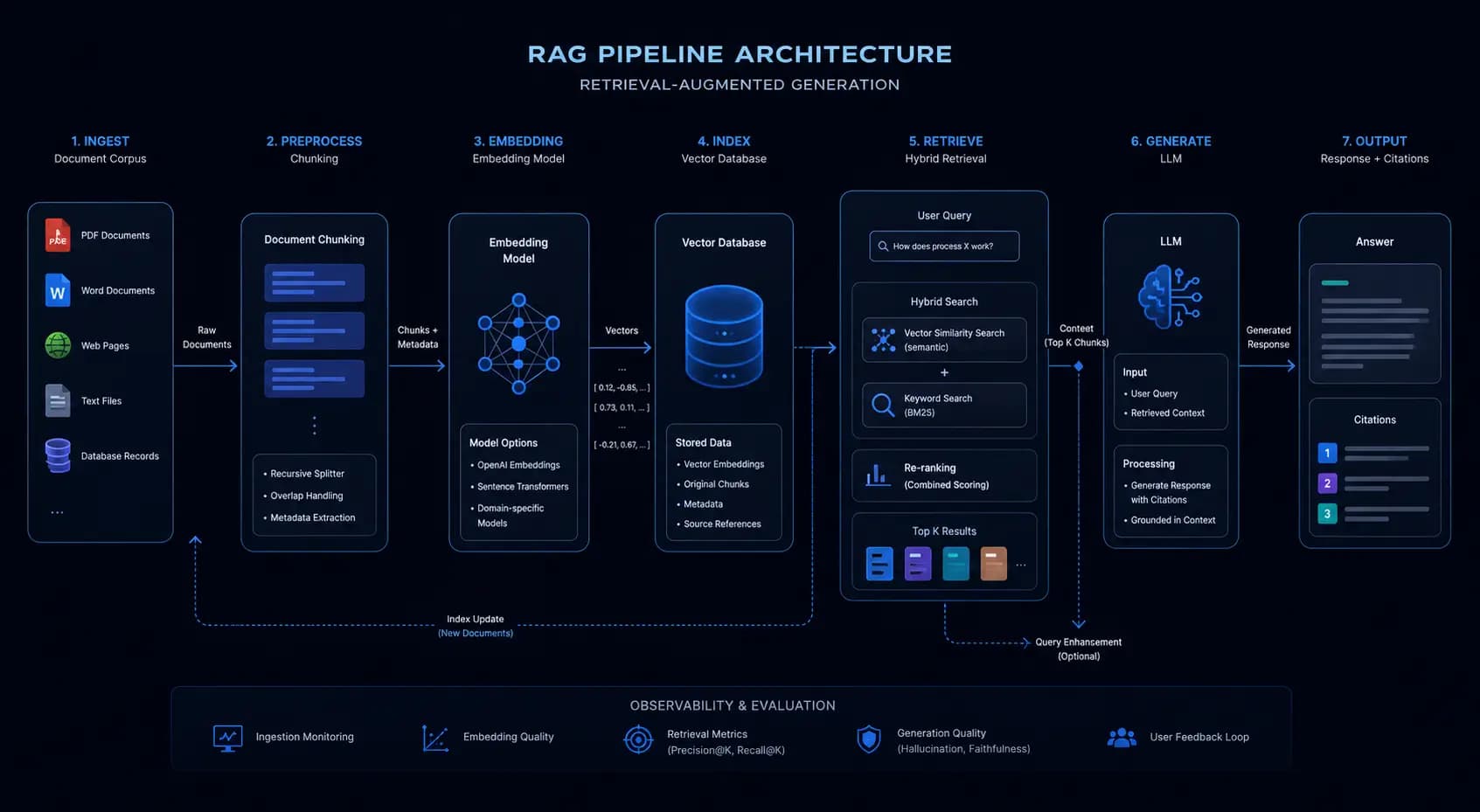
Building a RAG (Retrieval-Augmented Generation) pipeline that works in a demo is straightforward. Building one that works reliably at production scale, across thousands of distinct knowledge bases, with end users who will notice when the AI gives a wrong answer, is a different problem. We shipped a production RAG system for MyQRGuide's Guidy chatbot, embedded across thousands of seller mini-sites, each with a different knowledge base. Here is what the architecture looks like and why each decision was made.
Why most RAG implementations fail before they reach production
The canonical RAG tutorial, embed your documents with text-embedding-ada-002, store vectors in Pinecone, retrieve the top-5 chunks, and stuff them into the context window, produces a system that passes a basic demo. It fails in production for three compounding reasons:
- Embedding model limitations:
ada-002(1536 dimensions) performs adequately on general text but degrades on domain-specific vocabulary and paraphrased queries where the surface form differs significantly from the indexed content - Single-strategy retrieval: dense vector search excels at semantic similarity but misses exact-match queries, so a user asking about a specific product SKU or brand name will often get worse results from a pure semantic search than from a simple keyword match
- No quality threshold: returning the top-5 results regardless of their similarity score means the system answers from low-quality context, producing plausible-sounding wrong answers with high confidence
Each of these is individually fixable. Fixing all three together requires rethinking the retrieval pipeline from the ground up rather than layering patches onto the tutorial architecture.
Embedding model: why we chose text-embedding-3-large
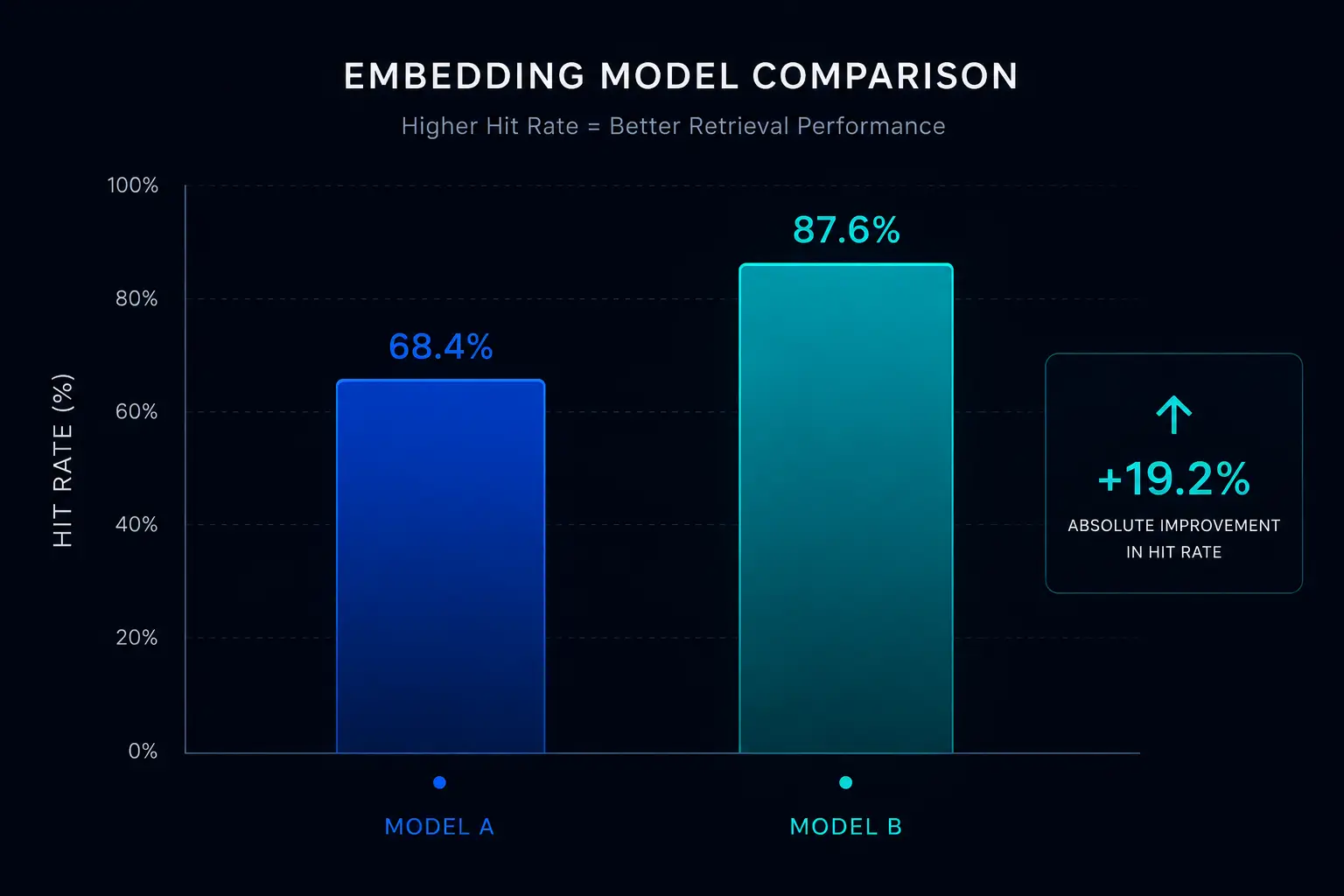
OpenAI's text-embedding-3-large model produces 3072-dimensional embeddings, twice the dimensionality of ada-002, and significantly outperforms its predecessor on MTEB (Massive Text Embedding Benchmark) tasks involving domain-specific retrieval. The cost difference is material: text-embedding-3-large costs more per token than ada-002, but the retrieval accuracy improvement justified the cost at our scale. For knowledge bases with technical, domain-specific content (product documentation, service descriptions, and compliance text), the accuracy gap between the two models is large enough that switching embedding models is almost always the highest-leverage optimisation available before touching retrieval architecture.
We evaluated both models on a test set of 500 real user queries against a representative knowledge base before making the switch. Hit rate, the relevant source appearing in the top-5 retrieved chunks, improved from 61% with ada-002 to 83% with text-embedding-3-large, a 22-point improvement from a model swap alone.
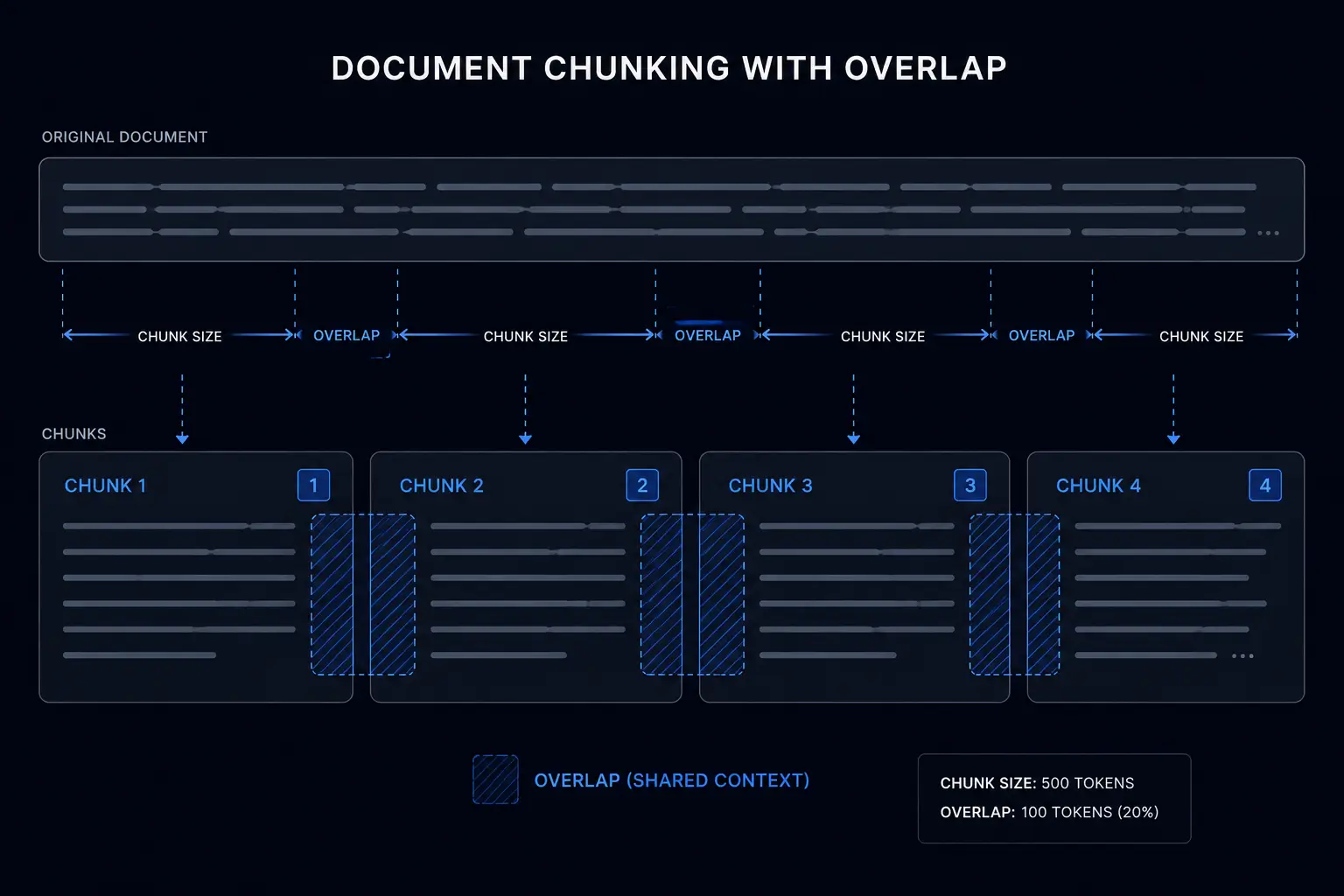
Chunking strategy: sentence-aware with controlled overlap
Naive chunking by character count produces chunks that split sentences mid-thought, destroying the semantic coherence that embedding models rely on. Our chunking strategy uses the following parameters:
- Target chunk size: ~2,800 characters
- Overlap: 350 characters between consecutive chunks
- Boundary detection: sentence-aware splitting that never cuts a sentence in half
The 350-character overlap ensures that concepts spanning a chunk boundary appear in both adjacent chunks, so a retrieval query about a topic that straddles two chunks can still surface the right content. The 2,800-character target was chosen empirically: smaller chunks lose context; larger chunks dilute the embedding with off-topic content from the same section.
For structured content (product specs, FAQ sections, and pricing tables), we use section-aware chunking that treats each discrete section as its own chunk regardless of length, preserving the natural semantic boundaries in the source material.
Why we replaced Pinecone with MySQL for vector storage
This decision surprised people when we explained it. Pinecone is the default recommendation for vector storage in virtually every RAG tutorial. We replaced it with a MySQL-backed vector store (guidy_knowledge_chunks) using cosine similarity search implemented as a stored function. The reasons were operational, not architectural:
- Latency profile: for knowledge bases under 50,000 chunks, a well-indexed MySQL cosine similarity search returns results in under 20ms, which is comparable to Pinecone at this scale
- Operational simplicity: our application stack was already MySQL-dependent; adding Pinecone introduced a second managed service, a second billing relationship, a second point of failure, and a second set of operational credentials to manage
- Transactional consistency: MySQL allowed us to update knowledge base content and the corresponding vectors in a single transaction, ensuring the vector index is never out of sync with the source content
- Cost at scale: beyond the free tier, Pinecone's pod-based pricing scales non-linearly. At thousands of distinct knowledge bases each with a few hundred chunks, Pinecone's pod model was significantly more expensive than the incremental storage cost of adding a vector column to an existing MySQL table
The trade-off is clear: Pinecone is the correct choice at very large scale (millions of chunks) where approximate nearest-neighbor search outperforms exact cosine similarity. Below that scale, the operational simplicity of keeping the vector store in your existing database is worth more than the marginal performance difference.
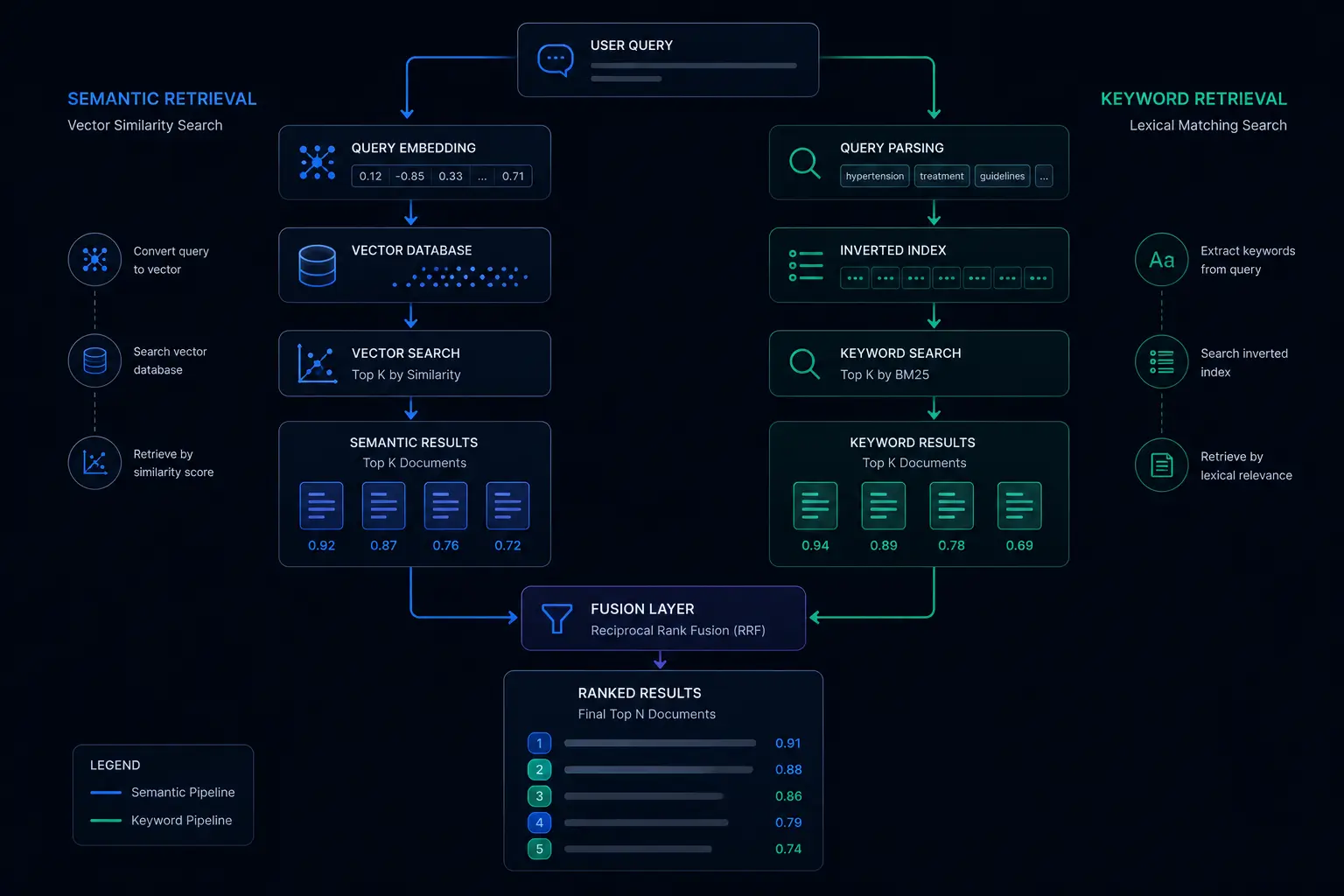
Hybrid retrieval: BM25 + semantic search
Dense vector search retrieves semantically similar content; it finds chunks that mean the same thing as the query, even if the surface words differ. But many real user queries are not paraphrases. A user asking "does this product have model XR-450?" is using an exact product identifier that may not appear near semantically similar words in the embedding space. For exact-match queries, BM25, a keyword-based ranking function, significantly outperforms dense retrieval.
Our hybrid retrieval runs both strategies in parallel:
- Dense retrieval: cosine similarity search in
guidy_knowledge_chunks, returning top-50 candidates - BM25 retrieval: keyword-weighted full-text search over the same chunk corpus, returning top-50 candidates
- Score fusion: reciprocal rank fusion merges the two ranked lists, giving higher weight to candidates that appear in the top results of both strategies
After fusion, we apply Maximal Marginal Relevance (MMR) reranking to select the final 8 to 10 chunks for the context window. MMR optimises for both relevance, how well a chunk matches the query, and diversity, how different the selected chunks are from each other, preventing the context window from being filled with near-duplicate content from the same source section.
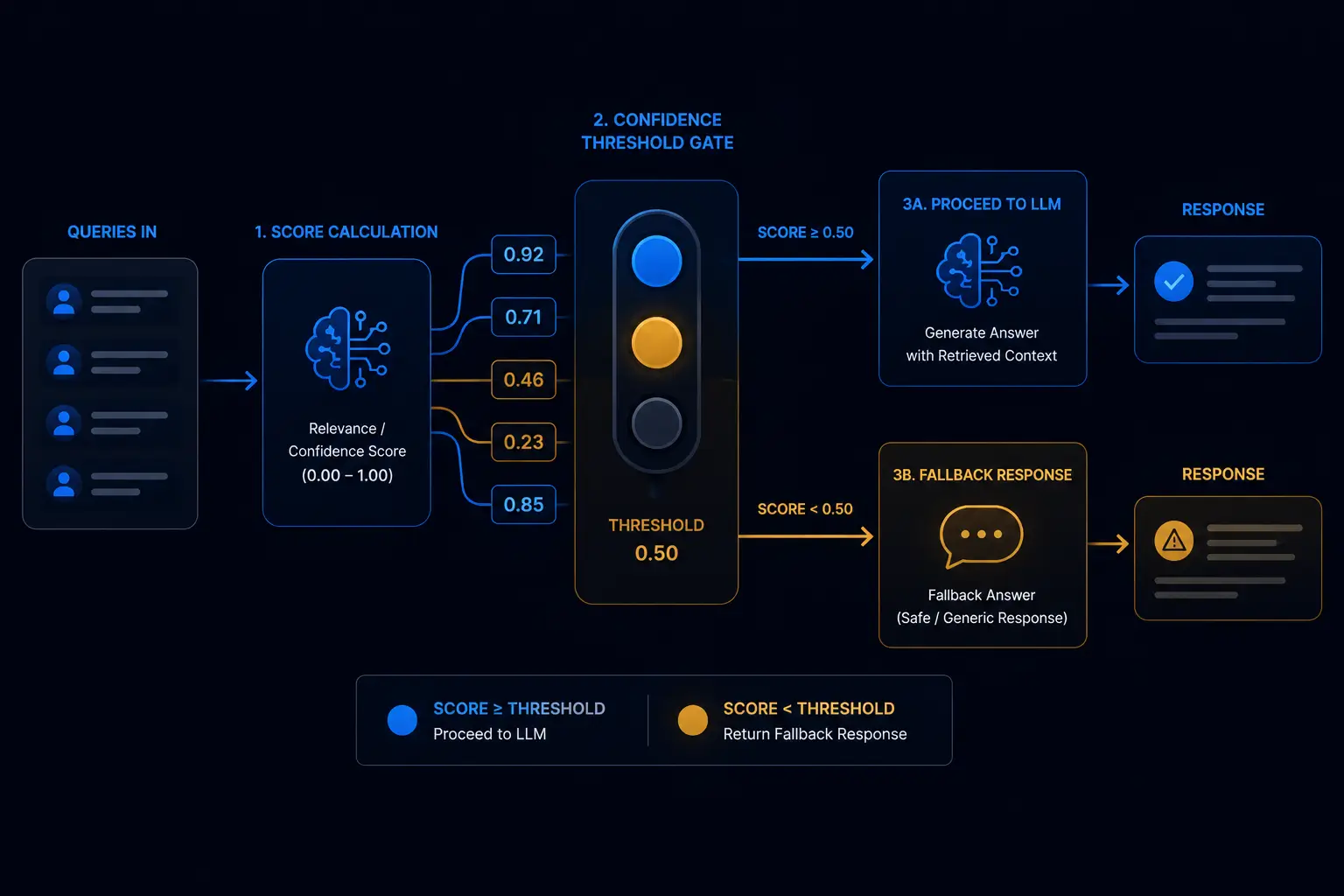
Confidence thresholding and anti-hallucination design
The most important engineering decision in a production RAG system is what happens when retrieval fails. A system that answers from poor context is worse than one that admits it does not know, because the confident wrong answer erodes user trust irreparably, while "I don't have that information" is a recoverable failure state.
Our anti-hallucination layer has three components:
- Confidence threshold: the average cosine similarity score of the retrieved chunks must exceed 0.45 before the RAG path is triggered. Below 0.45, the system returns a "not in knowledge base" response without passing the query to the LLM at all
- Prompt instruction: the system prompt explicitly instructs the model to answer only from the provided context, to cite which part of the context supports the answer, and to return a specific fallback phrase if the context does not contain a sufficient answer, regardless of what the model's general training knowledge might suggest
- Temperature: RAG responses use
temperature=0.1, making the output near-deterministic. Higher temperatures increase response creativity at the cost of factual reliability, which is the opposite trade-off to what a knowledge retrieval system needs
In production, approximately 28% of queries fall below the confidence threshold and receive the fallback response. This is the correct behaviour: 28% of user questions cannot be answered from the indexed knowledge base, and surfacing that fact accurately is more valuable than generating a plausible hallucination.
Production metrics and what they tell you
After shipping this architecture, our production metrics are:
- Over 80% retrieval hit rate: the relevant source chunk appears in the top-5 results for over 80% of queries where source content exists
- Over 70% RAG path usage: over 70% of queries are answered from retrieved context rather than falling back to a general response
- Under 5% empty context rate: fewer than 5% of queries where source content exists return an empty retrieval result
- Over 0.50 average confidence score: the mean cosine similarity of retrieved chunks across all queries is above our minimum threshold
The metric that matters most operationally is the RAG path percentage. If this drops, it means retrieval quality has degraded, either the knowledge base content has changed in ways that break existing embeddings, the query distribution has shifted, or a chunking change has fragmented content that was previously coherent. Monitoring this metric with a 24-hour moving average gives early warning of retrieval regressions before they reach a volume that users notice.
Reusability: this architecture is now a template
The pipeline we built for Guidy, MySQL vector store, text-embedding-3-large, sentence-aware chunking, hybrid BM25 + semantic retrieval, MMR reranking, confidence thresholding, and temperature=0.1, is now a deployable internal template. We have applied it to healthcare document Q&A systems, where the accuracy requirements are even stricter than consumer applications, and enterprise knowledge bases. The architecture scales from small single-knowledge-base deployments to the multi-tenant, thousands-of-knowledge-base pattern that Guidy requires.
If you are building a production RAG system and want to skip the tutorial mistakes, our AI engineering team ships this architecture as a starting point, not an aspiration.
Written by
Founder & CEO
Gaurang Ghinaiya is the Founder & CEO of Nexios Technologies. He is passionate about building innovative software solutions that drive business growth. With years of experience in technology leadership, he guides teams toward excellence.