AI Engineering
4 articles
Filter by topic
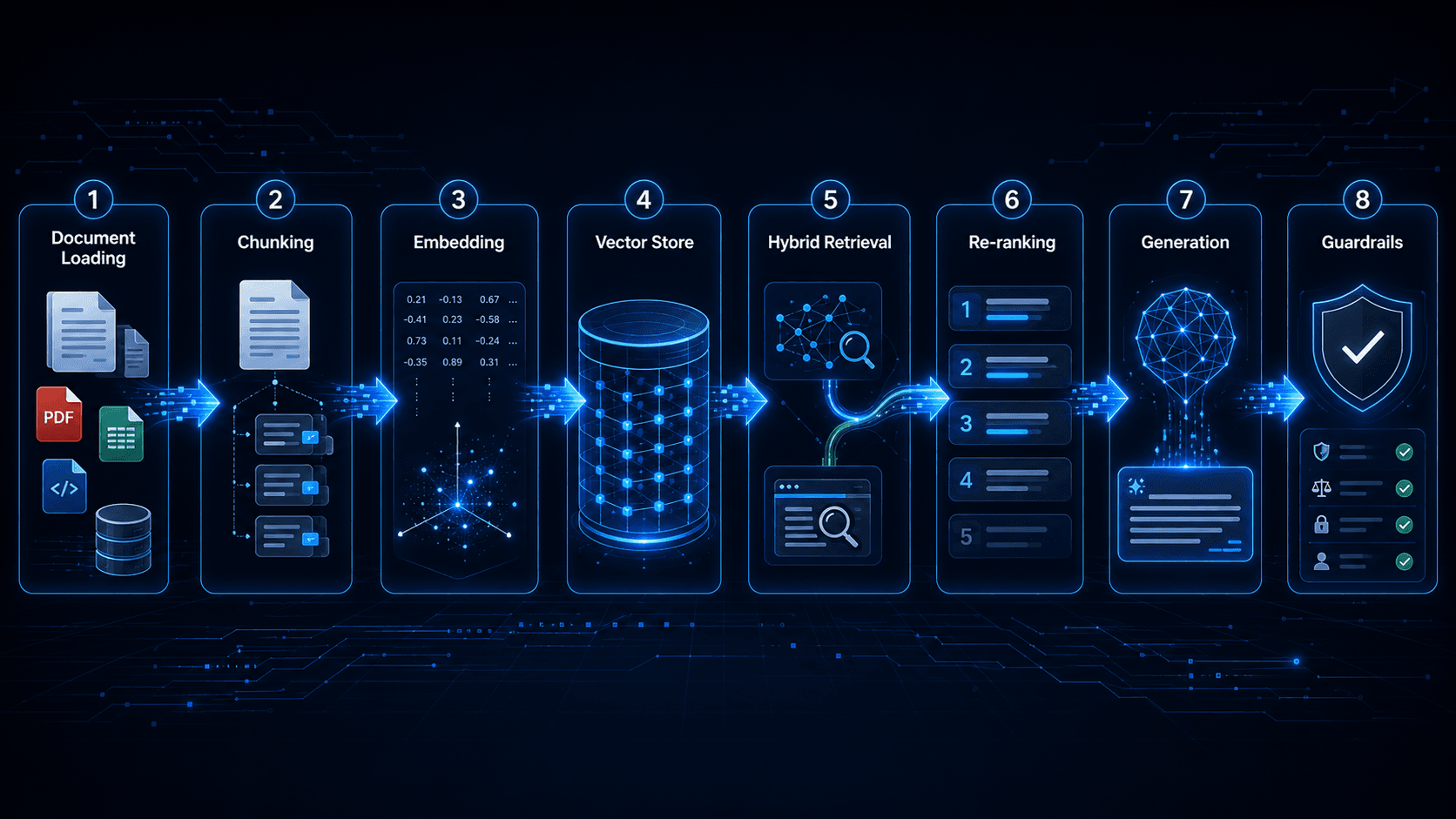
Production RAG Architecture: Chunking, Embeddings, Hybrid Retrieval, and Anti-Hallucination. The Complete Guide
RAG is not a single thing. It is a pipeline with seven or eight discrete engineering decisions, each of which significantly affects accuracy. This is the complete architecture guide based on what we have learned shipping RAG systems to production.
Gaurang Ghinaiya
June 3, 2026

LLM Integration Patterns for B2B SaaS: From API Wrapper to Production-Grade AI Feature
Adding an LLM to your B2B product is not the same as building a consumer chatbot. Token costs, reliability, latency, multi-tenant data isolation, and auditability all look different when your customers are businesses using your AI feature in production workflows every day
Gaurang Ghinaiya
May 28, 2026
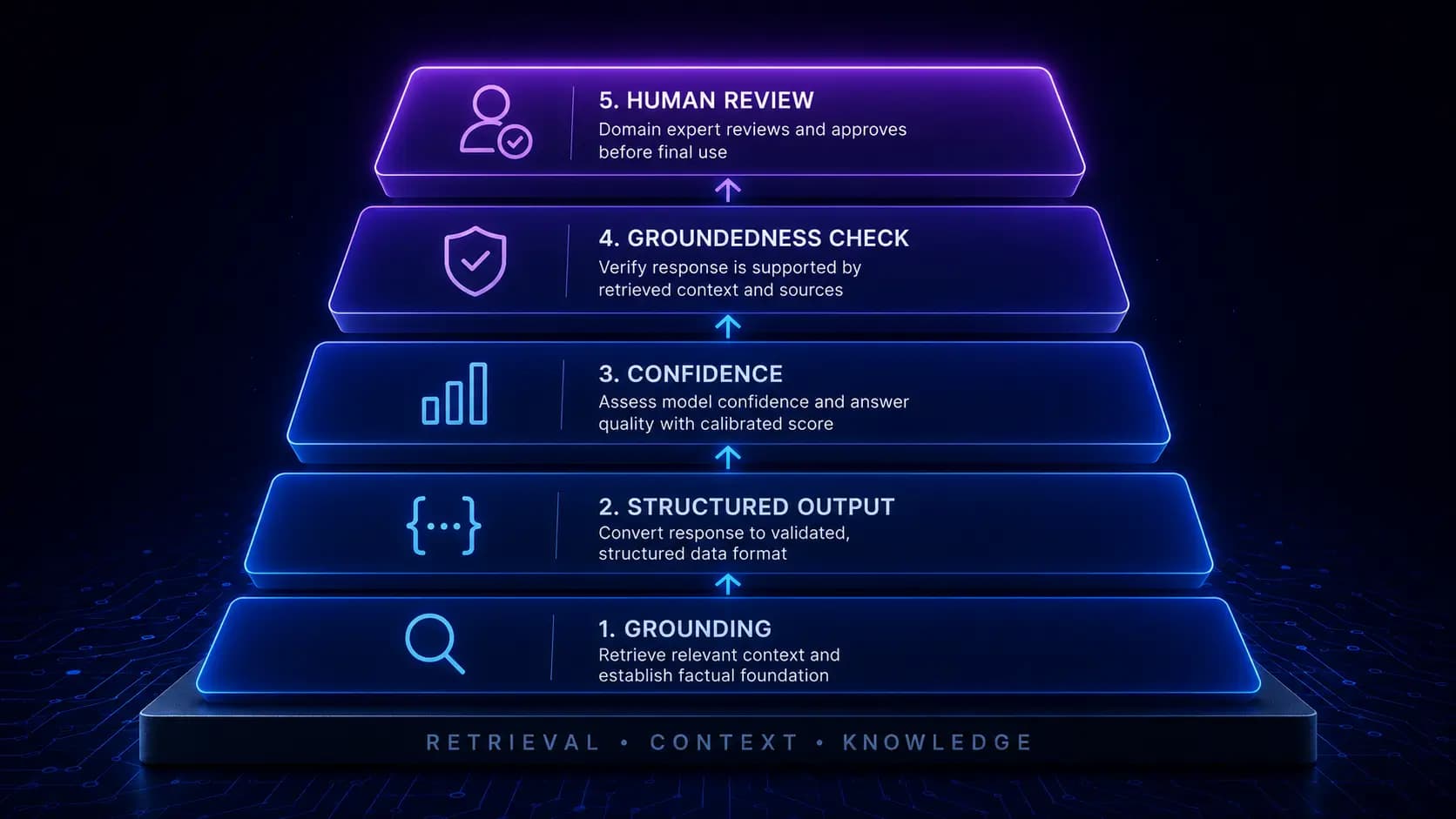
The Anti-Hallucination Stack: Engineering LLM Products That Are Accurate Enough to Trust
Hallucination is not a bug you fix. It is a property of the model that you design around. The engineering work involves building detection layers, confidence mechanisms, and fallback behaviors that make a product trustworthy, even when the model is wrong.
Gaurang Ghinaiya
May 4, 2026

Multi-Tenant SaaS Architecture: Isolation Models, Data Strategies, and the Decisions That Scale
The multi-tenancy architecture decision you make when you have 10 customers is the architecture you will live with when you have 10,000. This is the tradeoff analysis for each isolation model and the implementation patterns that hold up at scale.
Gaurang Ghinaiya
April 8, 2026
Let's talk
Have a project in mind?
Tell us about your project below, or pick another way to reach us. Average response time: under 4 business hours.